Shrunken Dimension is a very special type of dimension when there is a requirement of higher level of summary and lower grain data is already available in the warehouse.
Before we dive in if you do not understand what is the grain of the dimension, it is important to understand.
Month could be a shrunken dimension of date, which could be connected to a fact which has grain of month like monthly sales. But this is a very classic example, let us deep dive a little with another example.
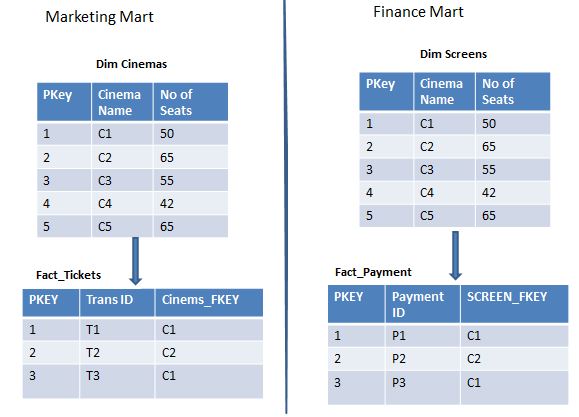
Considering the Online Movie Ticketing business scenario, we would have 2 tables, a fact for Ticket sales and a related dimension of the Venue for which sold the ticket.
If customer need to view the total consolidated Sales at city level rather than Venue level, we could create a separate dimension for City and a separate fact table for Consolidated Sales. The image below demonstrates the same:

In the example above we have created a base dimension and Shrunken dimension separately. If needed we could also create the Shrunken dimension from the base dimension, once it is loaded. Again it totally depends on the business requirements and the type of source system you are dealing with.
Before we dive in if you do not understand what is the grain of the dimension, it is important to understand.
Month could be a shrunken dimension of date, which could be connected to a fact which has grain of month like monthly sales. But this is a very classic example, let us deep dive a little with another example.
Considering the Online Movie Ticketing business scenario, we would have 2 tables, a fact for Ticket sales and a related dimension of the Venue for which sold the ticket.
If customer need to view the total consolidated Sales at city level rather than Venue level, we could create a separate dimension for City and a separate fact table for Consolidated Sales. The image below demonstrates the same:

In the example above we have created a base dimension and Shrunken dimension separately. If needed we could also create the Shrunken dimension from the base dimension, once it is loaded. Again it totally depends on the business requirements and the type of source system you are dealing with.